
2020年2月11日 第521页
-

产品优势_X-Pack Spark计算服务_云数据库 HBase 版
产品优势 X-Pack Spark服务和开源Spark的对比: 特性 开源Spark X-Pack Spark服务 产品能力(多数据源) 页面一键关联阿里云Cas...
-
Spark对接DRDS快速入门_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
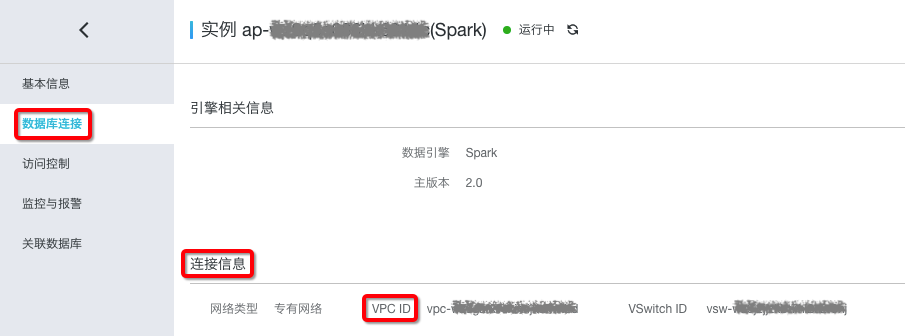
Spark对接DRDS快速入门 简介分布式关系型数据库服务(Distributed Relational Database Service,简称 DRDS)是阿里巴巴致力于解决单机数据库服务瓶颈问题而自主研发推出的分布式数据库产品。DRDS 高度兼容 MySQL 协议和语法,支持自动化水平拆分、在线平滑扩缩容、...
-
Spark对接Phoenix4.x快速入门_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
Spark对接Phoenix4.x快速入门 简介Phoenix擅长在线简单查询,复杂分析场景不适用。通过分析集群可以加强对Phoenix中数据的分析。当前云HBase支持Phoenix4.x(对应HBase1.x版本)和Phoenix5.x(对应HBase2.x版本)两个版本,分别采用重客户端和轻客户端模式,在...
-
分析集群管理_X-Pack Spark计算服务_云数据库 HBase 版
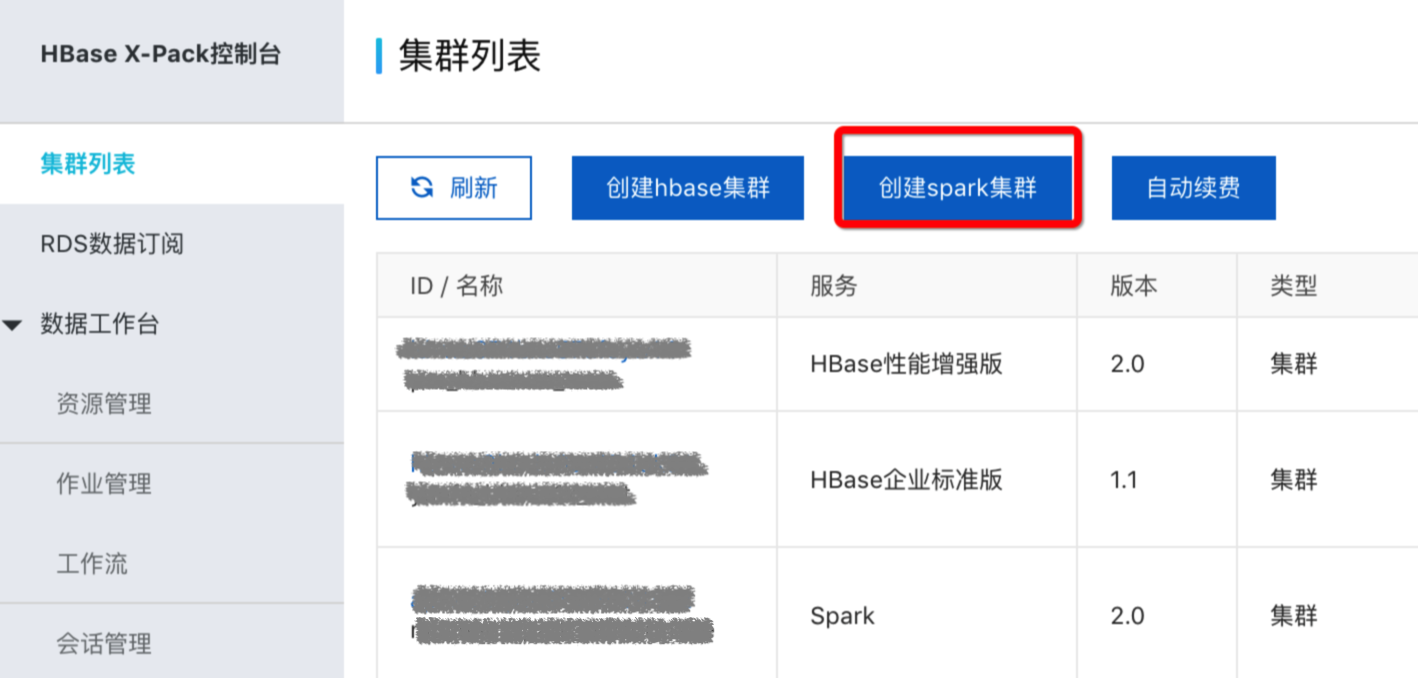
分析集群管理 集群创建在云HBase控制台点击“创建spark集群”,然后选择分析集群的master及core节点规格,创建分析集群。 注:分析集群创建好后,在云HBase控制台,集群ID以“ap”开头,同时“服务”会标注为“Spark”。 分析集群使用 服务接口:分析集群对外提供SQL服务Thriftse...
-
Spark对接Phoenix5.x快速入门_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
Spark对接Phoenix5.x快速入门 简介Phoenix擅长在线简单查询,复杂分析场景不适用。通过分析集群可以加强对Phoenix中数据的分析。当前云HBase支持Phoenix4.x(对应HBase1.x版本)和Phoenix5.x(对应HBase2.x版本)两个版本,分别采用重客户端和轻客户端模式,在...
-
Spark对接MaxCompute快速入门_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
Spark对接MaxCompute快速入门 简介大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。这里主要介绍通过“数据工作台”使用Spark对接MaxCompute数据表的使用方法。 前置条件 MaxCompute工作空间已创建。本例中MaxCompute...
-
快速开始_数据工作台_X-Pack Spark计算服务_云数据库 HBase 版
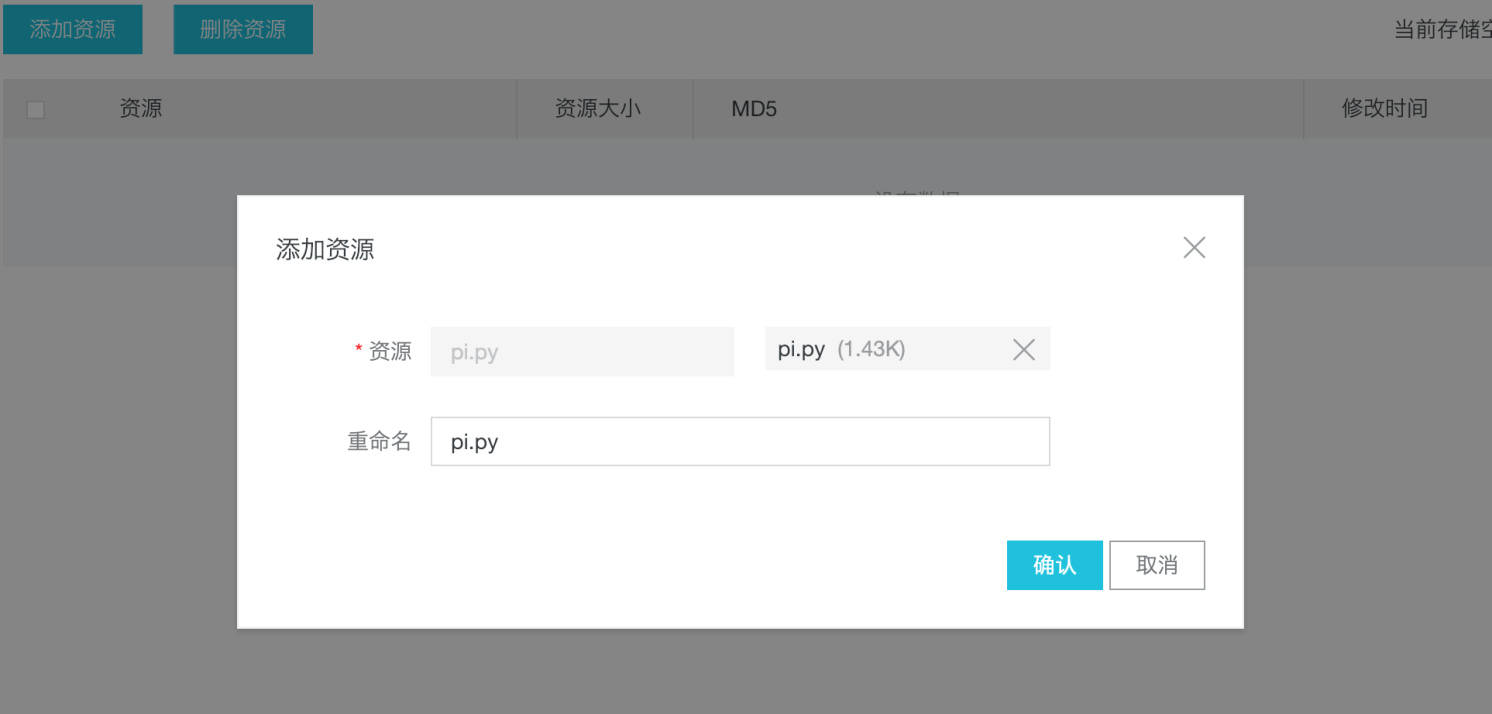
快速开始 我们先从一个最简单的作业场景开始:如何运行spark python pi example作业。 添加资源可以直接从这里下载:pi.py。然后从本地上传pi.py到数据工作台。 创建作业创建一个作业,然后在作业内容填写最简单的例子:运行一个pi.py脚本。 运行作业然后点击“运行”,提交到集群运行。就可...
-
Spark对接RDS快速入门_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
Spark对接RDS快速入门 简介阿里云关系型数据库(Relational Database Service,简称RDS)是一种稳定可靠、可弹性伸缩的在线数据库服务。基于阿里云分布式文件系统和SSD盘高性能存储,RDS支持MySQL、SQL Server、PostgreSQL、PPAS(Postgre Plus...
-
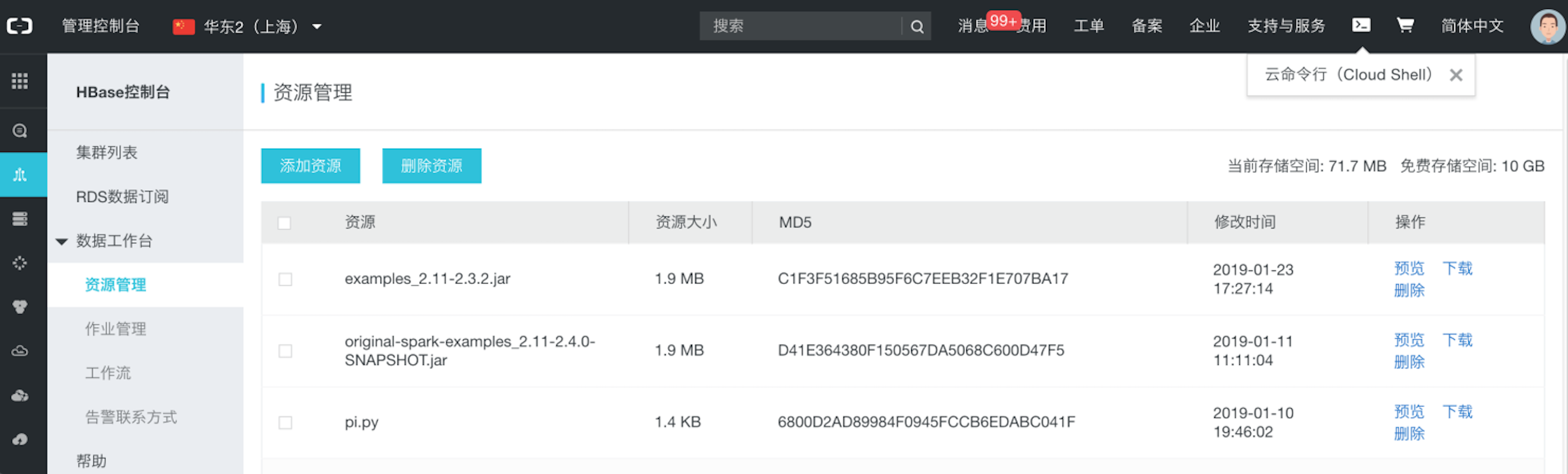
资源管理_数据工作台_X-Pack Spark计算服务_云数据库 HBase 版
资源管理 资源管理为用户提供代码、脚本、jar包等资源的托管功能。用户可以上传、预览、下载、删除资源。上传的资源可以在Spark作业里面使用到。目前免费提供10G的存储空间。入口:https://hbase.console.aliyun.com/hbase/cn-shanghai/workspace/resou...
-
Spark对接TableStore快速指导_Spark ETL&Streaming数据源连接器_X-Pack Spark计算服务_云数据库 HBase 版
Spark对接TableStore快速指导 简介表格存储(TableStore)是阿里云自研的面向海量结构化数据存储的Serverless NoSQL多模型数据库。 这里主要介绍通过“数据工作台”使用Spark对接TableStore数据表的使用方法。 前置条件 TableStore 实例已创建。本例中Tabl...